By Erin Wolcott, Assistant Professor of Economics, Middlebury College
Earlier this month, I invited a long-time friend, Quoctrung Bui, to campus. Bui and I know each from working our first job after college crunching data as research assistants at the Federal Reserve Board in Washington, DC. These days Bui is a graphics editor at the New York Times, where he covers social science and policy for The Upshot. He specializes in writing stories accompanied with data visualizations that help readers process the numbers.
At a workshop sponsored by the CTLR and DLA, Bui discussed with faculty what it’s like to be a graphics editor, how faculty can get their research picked up by the media, and what Middlebury students can do to prepare themselves for potential careers in data journalism. The conversation also turned to helpful coding and publication tools (see below for Bui’s recommendations).
Quactrong Bui.
To publish an Upshot article, Bui generally works with a team. He used the word “barnacle-ing” to describe how these teams are formed. If one editor comes up with an idea, other editors “barnacle” on to the project because they find it interesting, and together they can publish better journalism than working against each other. Initial ideas often come from sifting through academic research (often on Twitter feeds of scholars, policy makers, and other journalists) in search of new data and compelling stories. From there, editors interview experts in the field and work with researchers to create The Upshot’s data visualizations. Success of a story is partly measured by the number of reader “clicks” and other online analytics.
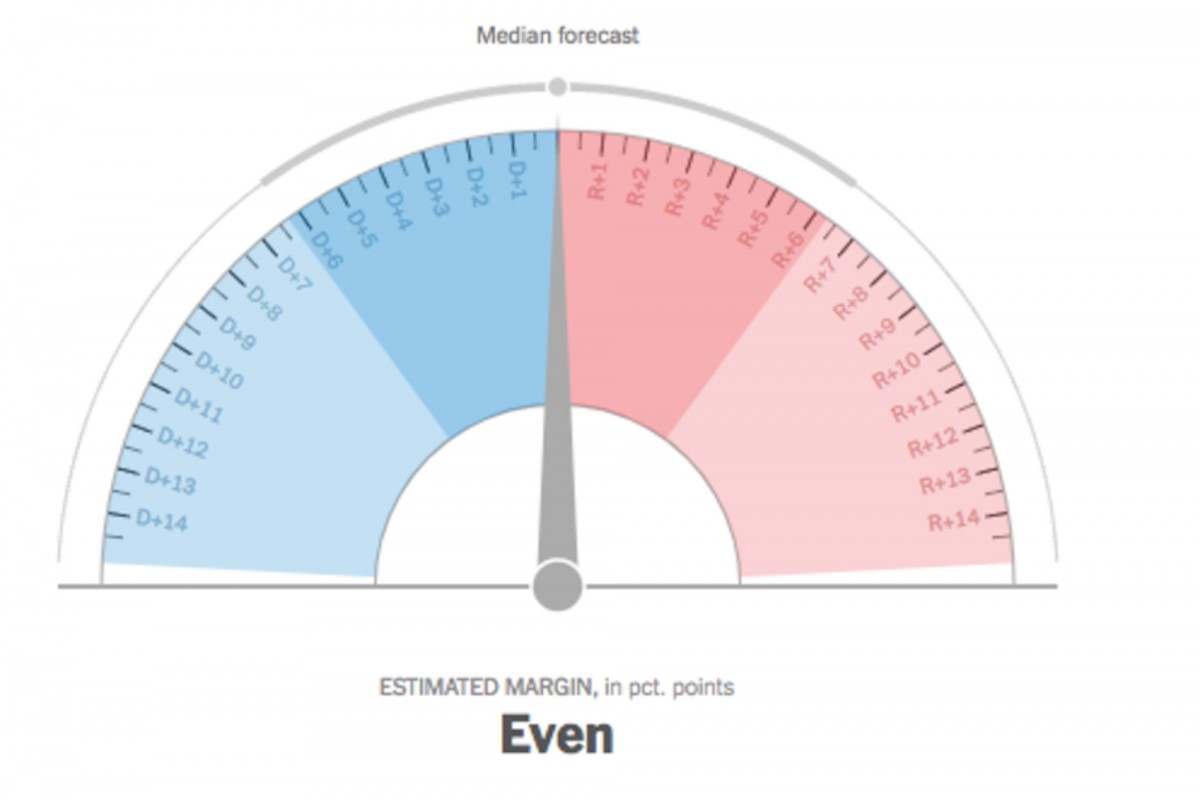
One data graphic that sparked much conversation during Bui’s workshop was the New York Times‘s election forecast “needles,” which both catch some of the excitement of elections and compress all sorts of factors in ways that might be hiding the data feeding these meters, particular around margins of error (also the needle has inspired a number of Internet memes and commentary).
The infamous election night “needle,” at the New York Times‘s The Upshot.
For students interested in a career in data journalism, the New York Times sponsors fall and spring semester internships in graphics. Bui recommends proficiency in R and other programming languages, but most of all a keen sense of journalistic curiosity about how data can suggest stories relevant to the Times’s readership.
Bui’s Quick Guide to Helpful Data Visualization Tools
In my opinion, the best model out for how publications should look like is Distill.
A chart/mapmaking tool I like for the web is Datawrapper.
I find Mapshaper does most of what you might want to do in QGIS or ArcGIS, but is free, web-based, and much faster.
DLA’s Digital Fluencies Series investigates what it means to develop more critical facility and engagement with digital technologies. Meetings usually combine 1-3 readings and a case study for hands-on exploration. Faculty, students, and staff at all levels of digital skill are welcome to attend.
Antoine Doré for Quanta Magazine.
Our meeting on algorithmic racism explored how we increasingly live in an algorithmic society, our everyday lives shaped by interactions with Google searches, social media platforms, artificial intelligence software, and myriad devices and programs that rely on the execution of computational algorithms. At the broadest level, We wanted to ask, updating Robert Staughton Lynd’s famous book-title phrase Knowledge For What?, algorithms for what? More specifically, we hoped to explore what it would mean to become “algorithmically fluent” and more critically aware of the ways in which algorithms reinforce or extend larger structures of racism, oppression, injustice, and misrepresentation. And how might we harness the power of algorithms for better ends in scholarship, teaching, inclusivity, freedom, and citizenship in the contemporary world?
We turned to the following readings and case study:
Much of our conversation pivoted on two issues: how do we become aware of the effects of algorithms in our lives as citizens, and what kind of curricular interventions at Middlebury might best prepare students for navigating a world of algorithms?
On the former question, we returned repeatedly to the need for awareness, while on the latter we pondered how to enhance this awareness in a liberal arts college curriculum. Our overarching sense seemed to be that not everyone must become proficient in designing algorithms as coders or programmers to develop more contextual understanding of how they function in the Internet and other digital technologies as currently designed. We can learn basic underlying histories and guiding principles for algorithmic construction that help us all better identify when algorithms are causing harm, when they turn into what Cathy O’Neil calls Weapons of Math Destruction.
We can also, fascinatingly, do the reverse: we can use algorithms as a way to glimpse deeper issues of structural racism (not to mention sexism and other isms that name systemic modes of injustice, violence, and suffering). Algorithms, we learned from our readings, get designed and implemented within social conditions that are already systemically racist; is it no wonder that they then, as computational processors of data, information, and knowledge, reproduce racism? What has been most striking, as Safiya Umoja Noble and Zeynep Tufekci show, is how the particular contexts in which algorithms now dominate our lives, amplify these underlying and persistent historical forces? The problem is not algorithmic thinking per se, but rather the frameworks in which algorithms are employed.
And what are these frameworks? We noticed a few from our readings and discussion:
Advertising as the business model for Silicon Valley. Our authors repeatedly pointed to the ways in which Google, Facebook, Twitter, and other dominant forces on the Internet are all driven by attracting attention to sell advertising. This, as Tufekci contends in the case of YouTube, seems to create algorithmic designs that intensify extremist views and controversy while hollowing out a common middle ground of cultural experience and exchange (although perhaps cat videos might sustain that common space, which is to say perhaps there are certain kinds of kitsch that create commonality!?).
The bubble effect of social media. Because social media carves up the distinction between private and public spheres in new ways, it undercuts previous assumptions and models about shared culture. Tufekci’s work on Twitter, Facebook, and Fergusoncatches the ways in which the idea of the public sphere has fragmented into a multitude of semi-public spaces. The network models that social media algorithmically generate pose new challenges for giving the public sphere and shared public culture a robust virtual life.
State power and government regulation. A focus on advertising points to the role of the state in possibly regulating algorithmic activities. However, Virginia Eubanksuncovers ways in which state power has also been misused to exacerbate long-running problems of managing the poor rather than addressing poverty itself. Sometimes this has to do with cynical political decisions or extreme political views, but the managerial-algorithmic complex operating in both corporate-commercial Silicon Valley spaces and governmental decisions may well be as crucial to confront as the problems of consumerist economics underlying the Internet infrastructure.
How does greater awareness of the role of algorithms in contemporary society relate to the need for increased numeracy? How might we better understand the logics and statistics and approaches of math, statistics, and numbers as part of our civic obligation when it comes to digital technologies, the Internet, and the presence of algorithms in larger systems of oppression? And how do we do so not in a Luddite fantasy of blaming the machines, but rather with a goal of liberation—or at least reform to systems that continue to sustain regimes of racial inequity and injustice?
These are just a few issues that arose in our conversation, which also touched on matters of how we handle the benefits and drawbacks of automation through algorithmic computation, whether the makers of algorithms are ethically responsible for their creations, at one point those who use the algorithms become ethically responsible for their actions, and how we might notice or imagine alternatives to the current technological systems that, despite the more wildly utopian rhetoric about digital culture, have not only reinforced long-running forces of racism, but even escalated them further. How can we devise practical solutions and reforms as well as continue to imagine more wild, utopian alternatives and imaginaries?
Raymond Biesinger for Politico.
In addition to noticing the presence of algorithms in our shared lives as citizens, our conversation also turned to the classroom and curriculum at Middlebury. How do we teach in new ways to advance digital fluencies when it comes to the relationship between algorithms and racism? A debate emerged between two models: does one concentrate on core courses that explore digital fluencies around topics such as the ethics of algorithms or should awareness and thinking about algorithmic thinking suffuse the curriculum across multiple disciplines?
Perhaps the answer is both should happen. Core courses in Computer Science, the social sciences, information environmentalism, philosophy, and history of technology can go deep with the many facets of algorithmic analysis. Our freshman seminars might all contain some kind of digital fluency component. There might be other moments to create cross-campus engagements with the problem and possibilities of the algorithm.
At the same time, heightened awareness of algorithmic thinking might also appear within many different disciplinary areas. The challenge would be to use the increased consciousness of what algorithms are up to in order to deepen student learning about particular fields of study. A good model for this approach might be found in Benjamin Schmidt‘s work on the effort to apply algorithmic thinking to specialized scholarship in literary studies and history (in his commentary on the Jockers/Swafford debates about the Syuzhet Package and sentiment analysis of nineteenth-century European novels). Here, a seemingly esoteric scholarly disagreement cracks open a view on issues not only of algorithms but also the history of the European novel. To be sure, we’ve moved away from racism in its contemporary or historical context in this instance, but we might be able to delve deeper into all sorts of topics such as racism via considerations of the algorithm in various departments, disciplines, courses, units of courses, and fields of study.
In short, we need the history and context of algorithms to understand their workings more critically; at the same time, we might be able to use the growing prevalence of algorithms in society—and debates about their effectiveness and accuracy—as opportunities to gain deeper comprehension of the histories, contexts, methods, approaches, modes of inquiry, information, data, and knowledge that algorithms now increasingly mediate.
We’re upgrading our library catalog software this spring, and as we do this, we have a chance to re-visit choices we’ve made in how we configure the system. One of those choices involves how we handle records pertaining to patron information. Legally, we are allowed to store borrowing records for our own internal purposes, provided we limit the use of this information to library staff, only sharing it outside of the library when compelled to do so by law enforcement via a subpoena. Historically, the library has never stored any information about material individual patrons have checked out once the materials are returned to us, largely because we believe that not storing that information at all is the best way to protect patron privacy, one of the core values of librarianship. (Individual patrons can currently choose to view their own borrowing histories through MyMIDCAT, but the library does not have access to that information.)
If, however, we did choose to keep this data, it would allow us to do some useful things. We would, for example, be better able to determine who may have damaged an item if we failed to notice a problem upon checking it in. With some additional programming, we might be able to build on top of this data a recommendation system that would enable us to suggest other materials to our readers based on the habits of similar patrons. We might conceivably also be able to gather aggregate usage statistics to see how our collections are used by discipline, by class year, or even, perhaps, by GPA, and to explore if there is any relationship between academic achievement and use of our resources. These potential uses are all very enticing, and might make our currently rather pedestrian catalog a bit more exciting and interactive.
We won’t be attempting any of that.
I write this a few weeks after Mark Zuckerberg, Facebook’s CEO, was summoned to Washington for two days of testimony in the wake of the disclosure that Cambridge Analytica had used Facebook’s API to collect personal data on hundreds of thousands of Americans as a means to influence the 2016 presidential election. As we’ve known for decades, when a service is free to a consumer, the consumer is not really the customer, but is instead the product; the actualcustomer is the advertiser (or political operative) that is paying for access to the personal data of the service’s users. Increasingly, the systems we buy come configured in a way to encourage us to collect massive amounts of data about our community. Computers are really, really good at doing this sort of thing. In turn, we need to also get really, really good at thinking about our values, our core principles, and the ramifications of the seemingly small choices that we make as we procure and configure these systems. And we need to be clear with our community about what data we are collecting, how we are protecting it, who has access to it, and how it is being used.
In our new strategic framework, we’ve identified critical digital fluency as one of the core elements of a Middlebury education. We’ve begun a series of workshops and conversations that will help us as a community develop a shared vocabulary about what critical digital fluency means, and what it looks like in terms of both technical skills and habits of mind. This is a timely development. We live and work in a world that is increasingly mediated by technology, and have to make choices both large and small that collectively result in how we live out all dimensions of our personal and professional lives. Creating community norms around privacy and data, and learning to think critically about what technologies we choose, and how we choose to configure them, must be a core part of our collective development of this newly defined fluency. In addition to being thoughtful, critical consumers of technology, we can also, through collective action, identify opportunities to positively influence the future direction of the technologies that we increasingly rely upon, to reclaim the scholarly commons, to resist and reject models where we are the product, and to help build new infrastructures that support our values.