
With the nominating phase of the congressional campaign just about over and the midterm elections less than four months away, you are going to see an increasing number of predictions, prognostications and more than a few statistically-driven forecast models purporting to tell us how the Republicans and Democrats are going to do in the House and Senate. Accordingly, I thought it might be useful to present a short primer on the types of forecasts you are likely to see, so that you can makes sense of the predictions.
Generally, you will encounter three types of forecasts. The first type are individual race-specific predictions made by the veteran handicappers like Charlie Cook, Stu Rothenberg and their associates. These predictions use a combination of on-the-ground reports, opinion polls and other bits of evidence to divide the field into safe, leaning and tossup (or their equivalent) races. With their descriptively detailed updates focused on the competitive races, these types of horse-race forecasts are in many respects the most interesting to follow, particular when they look at the high-profile Senate races. Right now, for example, Cook is predicting that the Republicans will gain between 4 and 6 Senate seats. Rothenberg puts the number at between 4 and 8. The Republicans, you will recall, need a minimum of 6 to regain a Senate majority so both handicappers see a Republican takeover as well within the realm of possibility. The implicit assumption in these models is that individual races can turn on factors idiosyncratic to that particular race, and thus the most accurate prediction depends on understanding these myriad influences. In short, if we want to know which party is going to control the Senate, you need to build from the bottom up by aggregating the results of the individual races.
The second type of predictions are those produced by the structural forecast models developed by political scientists. In contrast to the handicappers like Cook and Rothenberg, these models eschew any interest in local detail in favor of macro-level factors, such as national economic growth, the president’s approval ratings and the number of exposed seats, to generate a prediction which is usually measured in terms of how many seats will be lost by the president’s party. The assumption built into such models is that fundamental national tides affect all races and thus all forecasters need to do is to measure those tides to generate an accurate prediction. To the best of my knowledge, Edward Tufte constructed the first such midterm House forecast model back in 1974 that was predicated on only two measures: the president’s approval and the annual growth in real disposal personal income per capita. In effect, he was modeling the outcome of the House midterm races – specifically, the share of the national popular vote the president’s party received – as referendum on the President’s performance.
Since Tufte’s pioneering effort political scientists have generated dozens of such forecast models, with most of them trying to predict the distribution of House seats between the two parties, rather than the overall vote share. Some early models focused solely on economic indicators. But most are predicated on variants of Tufte’s model, with measures for presidential approval included. More recent versions include additional variables. These might include “seat exposure” (which party has more seats on the line); a “surge and decline” variable (the idea is to capture the effect of the decline in midterm turnout based in part on how the parties did in the previous presidential election); and a time in office variable to capture the waning influence of a party that has held the presidency for a long time. The most recent innovation to these models – and one that I will discuss in a moment – is to include a generic vote variable based on national surveys that ask respondents which party’s candidate they plan to vote for in the midterm election.
In assessing these structural forecasts, you should keep two considerations in mind. First, most of the models are based on midterm elections occurring during the post-World War II era. So they are predicated on a very limited numbers of cases – 2014 is only the 17th midterm election in that period – which means that even the most accurate predictions have a very wide margin for error. In assessing the prediction of a particular model, you should always look to see if a prediction interval is provided in addition to the predicted seat outcome. Moreover, as Ben Lauderdale and Drew Linzer have cautioned in their critique of presidential forecast models, there is a tendency with a sample this small for modelers to over-fit their predictions by basing them too closely to the particular elections studied. Nonetheless these models are theoretically the most interesting because, when done well, the modelers are very explicit in explaining why midterms turn out the way they do. So we learn the most from these efforts in terms of understanding the dynamics driving election outcomes. Note that these are one-shot deals – once the numbers are plugged in, a forecast is generated and that is that. There’s no updating based on new data.
The final set of forecast are what might be called mixed models. Typically, these start out with a variant of a structural mode (a prior, to use Bayesian terminology), but then the prediction generated by that model is updated based on race-specific polling data. By the time Election Day rolls around, most of these mixed models will be mostly poll-based, which means (as Drew Linzer demonstrated so effectively in the 2012 presidential election) they are likely to be very accurate. These are the models featured at the Washington Post’s MonkeyCage’s Election Lab or the New York Times’ Upshot site. The basic idea behind these efforts is that if you want to know how people are likely to vote in the 2014 midterm, you should probably ask them and incorporate their response into your forecast.
You might think these mixed models would all generate basically the same forecast. As of today, however, they are not. The MonkeyCage, for example, is giving Republicans an 86% chance of retaking the Senate. The Time’s Upshot, on the other hand, gives the Republicans only about a 59% chance of taking the Senate. Why the difference? As the MonkeyCage’s John Sides explains here, it is partly because as of today the Upshot is likely weighting the polling data, which is a bit more favorable in some states to the Democrats, more heavily than is the MonkeyCage. So, which forecast is more accurate? I don’t know, and neither do they! But that is probably beside the point since it is likely that the two models’ predictions will converge as we get closer to Election Day.
The more important point is that this combination of structural models and polling data is likely to produce a more accurate forecast than either approach alone. (For the more technically-minded among you, Simon Jackman explains why here.) The use of mixed forecasting is more prevalent now because of advances in computing power and the greater ease of access to polling data. Still, the forecasts are not foolproof – pay attention to that confidence interval when evaluating predictions! – which means that in a very close election cycle, as this one appears to be, none of these approaches may be precise enough to nail down who will control the Senate with perfect accuracy. (Control of the House appears not to be in play at all this cycle.)
Of one thing I am sure. In the face of forecast uncertainty many of you will cherry pick the model whose outcome you like the best, while damning those you disagree with for their bad data, faulty assumptions and poor methodology. If you are one of those who believe in advocating the equivalent of “unskewing the polls”, I apologize in advance for injecting a dose of reality, no matter how unpleasant, into your political fantasy world in the coming months. I promise to do so as gently as possible.
Now let the forecasting begin!
UPDATE 5 p.m. Sam Wang has waded in with his own Senate forecast that puts the projected final Democratic seat total at either 49 or 50. He makes the important point that a small swing in the partisan share of the vote is going to determine which party controls the Senate – it’s that close! See his post on the topic here.




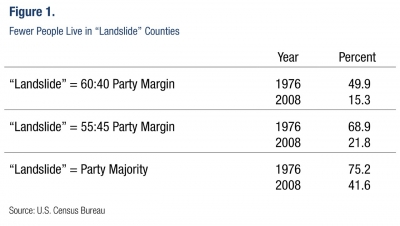
 More importantly, questions like those in the Washingtonian exercise, or in the recently released Pew survey on political polarization, that ask where we prefer to live based, in part, on political preferences, aren’t very good at telling us where we actually live. That is because as Clayton Nall and Jonathan Mummolo
More importantly, questions like those in the Washingtonian exercise, or in the recently released Pew survey on political polarization, that ask where we prefer to live based, in part, on political preferences, aren’t very good at telling us where we actually live. That is because as Clayton Nall and Jonathan Mummolo