by Robert K. Nelson, Scott Nesbit, and Andrew Torget
The History Engine as a Teaching Exercise
In a recent article about the contours of history department curricula across the country, Steven D. Andrews notes that
Many students do not “do history” until deep into their college careers, sometimes in the last semester of their senior year. It is only then, in some kind of seminar class, that students experience the process so familiar to historians: identifying their own questions, selecting their own sources, pursuing those sources and constructing arguments, documenting the research process, producing multiple drafts and rewrites, and finally presenting the work in a formal document. For some students, the first comprehensive use of the skills of a historian may be the final act of their education.
This delay in introducing to students the practices of historical inquiry is at odds with what many, perhaps most, historians would prefer, a lamentable if understandable product of the distinct goals of lower- and upper-division courses. The former tend to emphasize, as Andrews suggests, “accumulation of information” about historical context, the latter the acquisition of the “thinking skills” of historical research, reasoning, and argumentation. It is often logistically challenging, sometimes impossible, to ask students to “do history” in lower-division classes simply because there is a lot of information for them to accumulate. Covering, say, roughly two centuries of American history in a survey course affords little time to ask students to engage in original research and formulate their own questions. The length of the “formal document” that Andrews mentions–perhaps a fifteen-page term paper or an even longer seminar paper that’s modeled on the articles that historians themselves produce–doesn’t help. It is, more often than not, simply impractical to ask students in lower-division history courses to engage in that kind of time-intensive, ambitious research and writing exercise (to say nothing of the daunting prospect of grading many longer student research papers in larger sections).1
One of the primary goals of the History Engine project has been to design a research and writing exercise modest enough in its analytical scope and its length that it allows students to “do history” long before a senior seminar or capstone course. (Another important goal, discussed below, is to capture this research to amass a large history archive.) The History Engine is an online archive consisting of thousands of “episodes” written and contributed by undergraduates. What we call “episodes” are concise historical narratives, short micro-histories about small moments in American history. An episode is much shorter than a fifteen- or twenty-page seminar paper; it’s roughly five hundred words in length. It does not draw upon a large number of sources requiring extensive research; instead, a typical episode generally is based upon a single primary source and one or two secondary sources. An episode doesn’t make an ambitious argument about some major question in American history; its scope is much more modest. Rather than a thesis-driven essay, an episode is instead an exercise in historical storytelling, a short analytical narrative unpacking a story from a primary source. An episode, for example, would not make an argument about the causes of the Civil War but might, say, recount the departure of a group of Southern settlers for the Kansas Territory in 1856 and place that event within the context of the conflict between antislavery and proslavery forces to control that territory.
A couple examples provide a sense of the scope and nature of episodes. An episode entitled “Southern Outrage” written by a student at the University of Richmond focuses on an 1835 letter to the editor in a Richmond newspaper that condemned Northern abolitionists; it explores how a Southerner turned the abolitionists’ critiques of anti-abolitionists and economic boycott tactics on their head. Another written by a Furman University student, “Local Chinese React to Imperial Decree,” is transnational in its focus, exploring the reaction of Chinese immigrants in New Orleans in 1911 to an imperial decree from the Qing Dynasty instructing them to cut off their queues.
But despite the brevity of an episode, its composition remains an intense and rigorous exercise in historical research, writing, and analysis. In fact, we have learned that writing succinctly often takes a great deal more thought than writing longer essays, and work in archives rarely proves to be an easy task. To produce their episodes, all students are asked to do original research using primary sources; many are directed or encouraged by their instructor to dive into local historical archives or special collections to find their primary source or sources. Primary source research is, of course, often simultaneously exhilarating and disorienting. It’s a more direct way of encountering the past and often prompts more questions than it answers. Once a student finds an interesting and evocative source that she would like to place at the center of her episode, she then turns to the secondary literature to understand, perhaps, something intriguing but confusing in her source, or, maybe, to situate her particular episode within a broader historical context. Typically, after she composes her episode she would upload it into the History Engine database as a draft (available to her instructor but not the public) along with associated metadata (dates, locations, tags, and citations). Her instructor might review the episode and ask for revisions, or might have students peer review each others’ episodes. After being vetted for accuracy and quality by the instructor, the episode is published, making it publicly available on the History Engine site.
The Engine‘s History
The first iteration of the History Engine was produced in 2005 at the University of Virginia and initially tested and refined in Ed Ayers’s lecture course “The Rise and Fall of the Slave South.” Like most digital history projects, the History Engine is a product of extensive collaboration. The development of the initial iteration of the project and its use in Professor Ayers’s course was only possible because of the contributions of a number of partners at UVA. The Digital Research and Instructional Services group at UVA’s Alderman Library with support from the Virginia Center for Digital History developed the first Web application and provided server space. Special collections librarians helped students in their research, providing orientations, suggesting sources, and providing extra staffing on the days immediately before the assignment deadline when large numbers of students descended on their holdings.
From the beginning, the History Engine was always envisioned as a multi-school project that would enable undergraduate students to share their work with students from multiple universities. That was made possible in 2006-2007 through funding awarded by the National Institute for Technology in Liberal Education (NITLE). That award funded the refinement and expansion of the application software. As important as the monetary funding was, the relationship to NITLE also connected the project with faculty at a number of NITLE-affiliated colleges and universities. During the fall semester of 2007, four faculty at Furman University, Rollins College, Wheaton College, and Juniata College began using the project, with a handful of faculty from other colleges and universities joining since then.
The feedback from faculty who used early versions of the History Engine in their classrooms has been extraordinarily useful as we continue to revise and expand the project. Most reported that composing such short narratives challenged their students to engage in more careful writing, and that introducing undergraduates to primary source research required more instructor guidance than a traditional essay assignment. Based on their experiences, we developed a teacher’s guide outlining best practices for bringing the project into the classroom. Such feedback, as an informal means of measuring learning outcomes, suggested that the project’s emphasis on active learning and development of critical thinking skills resonated in the classroom. In a recent article reflecting on their use of the project, a collection of NITLE-affiliated teachers concluded that the History Engine “presented us new ways to teach the concept of historical significance” that “energized our teaching and intensified our students’ encounters with the past.”2
Since the summer of 2008 the History Engine has been hosted, redeveloped, and expanded at the Digital Scholarship Lab at the University of Richmond. During that period the Web application software for the History Engine has been completely redeveloped, making it more stable, modular, and extensible.3 More exciting than these largely invisible changes have been the additions of historical visualizations–maps, timeplots, tag clouds–that situate dozens or even hundreds of episodes in relationship to one another spatially, temporally, and topically.
The History Engine as a History Archive
These visualizations begin to realize the History Engine’s other main goal: to build a large history archive that would be both interesting and useful to students, the general public, and historians. Currently the History Engine contains several thousand episodes, and we hope it will eventually contain tens of thousands of episodes. Taken together, these collected episodes represent a fine-grained account of U.S. history. Even with tools as simple as a basic text search, the History Engine database has the potential to become a large interpretive finding aid for historical sources located in archives and libraries across the country.
One of the exciting aspects of this project is the possibility for leveraging the metadata associated with each episode to produce historical visualizations. When a student uploads an episode into the History Engine they include a number of pieces of metadata—the time and place the episode happened as well as tags or keywords that identify the issues addressed within the narrative. During the last year we have been working on developing visualization tools that use this metadata to allow users to navigate through and see patterns amid the complexity of the History Engine‘s thousands of episodes.
At times, mapping episodes reveals context that would otherwise be difficult to glean from the text of the episodes alone. For example, one episode located in Brooke County Virginia tells of the 1855 expulsion of five northern students for suspected abolitionism. That antislavery activism had infiltrated a religious college in the U.S.’s largest slave state only five years before the Civil War is, at first glance, surprising. When plotted on a map, however, the episode is more explicable and carries additional meaning. Brooke County, one discovers, was in the far northern tip of what is now West Virginia. It’s just forty miles from Pittsburgh, farther from what would soon be the Confederate capital, Richmond, than it was from one of the hotbeds of abolitionist activity, Rochester, New York. Mapping the episode suggests other conclusions not explicitly suggested in the text of the episode itself, namely how far north slavery reached.
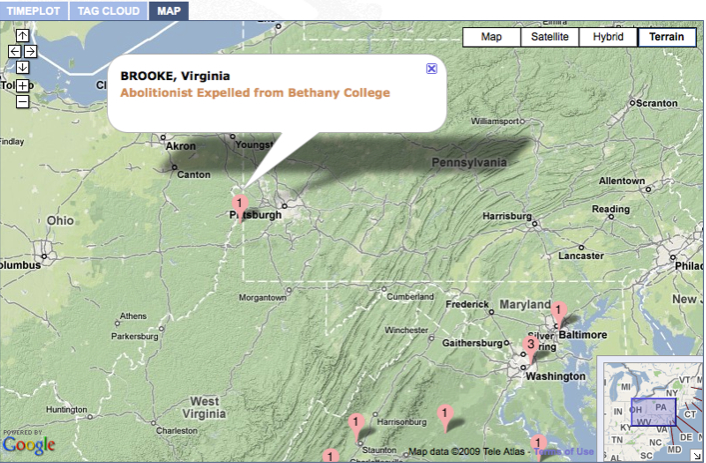
Figure 1: Mapped location of Brooke, Virginia
Once mapped, this episode suggests not simply how bold the young antislavery students were but how little room for compromise on the issue existed in even the most distant, peripheral corner of the South.
Visualizing how episodes align over time is likewise revealing. The History Engine‘s timeline reveals that students have written about debt most often when investigating the 1870s and 1880s, times of dizzying economic dislocation and concurrent political fights over the possibilities of debt adjustment.

Figure 2: Search results for “debt” displayed on timeplot
What student narratives reveal is how the effects of public and private borrowing rippled across the Gilded Age. Episodes detail, through the diary of a company clerk, the collapse of the Northwest Pacific Railroad, which declared bankruptcy following the Panic of 1873. This panic caused the failure of some of the nation’s largest companies. But as episodes mapped onto the timeline show, it also led to the collapse of local credit markets and, ultimately, helped bring about the end of Reconstruction as white northern Republicans became more concerned with economic recovery in the North than with black civil rights in the South. These forces converge in some episodes; one narrates the 1877 seizure of the property of Martin Joson, a Natchitoches, Louisiana freedman, on account of his debts to a white neighbor, showing how the tightening of local credit hit southern black landholders especially hard as they lost power and influence at the state and federal levels of government.
We have high hopes for the History Engine as we continue to develop the project. As the archive grows to include tens of thousands of episodes, we hope it becomes a valuable finding aid and a rich vein for historical visualization. Perhaps more important than the History Engine as a product–as a digital archive–is the opportunity it offers undergraduate students as a learning exercise that provides them an opportunity to “do history,” to actively grapple with the remnants of the past and the work of historians in order to make sense of and better understand some aspect of American history. For any instructors reading this who would be interested in having their students participate in and contribute to the project–or just want to offer a comment, suggestion, or critique–contact us through the History Engine website.
Notes
1. Stephen D. Andrews, “Structuring the Past: Thinking about the History Curriculum,” The Journal of American History (March 2009), http://www.historycooperative.org/journals/jah/95.4/andrews.html. [return to text]
2. Lloyd Benson, Julian Chambliss, Jamie Martinez, Kathryn Tomasek, and Jim Tuten, “Teaching with the History Engine: Experience from the Field,” Perspectives (May 2009), http://www.historians.org/perspectives/issues/2009/0905/0905for15.cfm. [return to text]
3. For those interested in the technical aspects of the Web application, it’s built using a number of open source resources: the code is PHP using the CakePHP MVC framework, the database is MySQL, and APIs used include Google Maps and the Simile Project’s Timeplot. [return to text]