
Once again I am reminded of the power – both good and bad – of social media.
My post today discussing the results from the latest Senate forecast models is up here at U.S. News. I should point out that I very much appreciate the opportunity to post there – it enables me to reach a wider audience and generates more feedback here at my regular Presidential Power site. So I encourage you to check the U.S. News site out on a regular basis – it includes some great writers, including former Middlebury student Rob Schlesinger.
But you should also know that I don’t write the titles to my posts there, and I certainly don’t get to create the twitter feed U.S. News uses to publicize the posts. So, when a tweet goes out from U.S. News linking to my post, as it just did, that reads “No, Nate Silver can’t predict who will win the Senate http://ow.ly/CAl3Q via @MattDickinson44”, and when CBS news correspondent Major Garrett retweets it to his more than 111,702 followers and when pollster Frank Luntz then forwards the link to his 48,000 followers, including Nate Silver, in this way – “@USNewsOpinion Them’s fightin’ words. (@MattDickinson44 vs. @NateSilver538)” – just remember: IT’S NOT MY FAULT!
In fact, if you read the post (please do!) you’ll see that I actually did not single out Nate Silver in any way that could be perceived as a knock on his forecasting abilities. Instead, I pointed out that the purely poll-based forecasting models have, over the last month, begun converging with the models that include fundamentals, exactly as I predicted they would in my previous post here. My other point, however, was that even though all the major forecast models that I follow are now giving Republicans a better than 50% chance of gaining enough seats to take a Senate majority, that is not the same thing as saying Republican control come November 4th is now a lock. Because so many of the Senate races remain close, with polling averages of less than 3% difference between the two candidates, and because the outcomes of those close races will affect who has a Senate majority, I don’t think the forecast models can really tell us right now who will control the Senate. With less than three weeks to go there still too much variability in the polling and, with the races so tight, the possibility that an unpredictable event will influence the outcome becomes greater. This isn’t a critique of the models – indeed, most of them (the Washington Post model is a notable exception) favor the Republicans by relative slim margins at this point, as this table indicates (purely poll-based forecasts in italics).
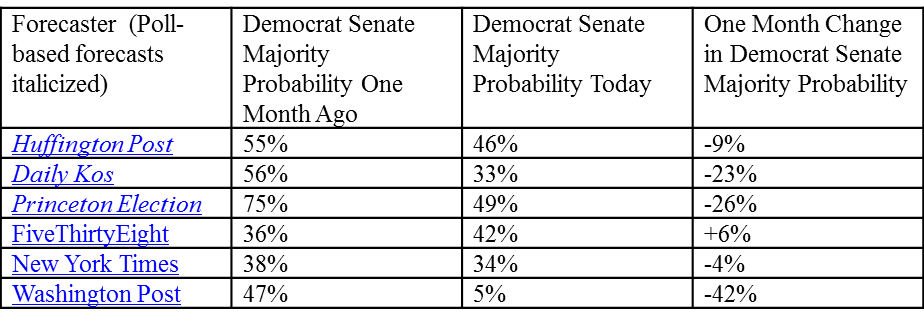 Put another way, the models are simply not precise enough for us to have much confidence regarding who will control the Senate on Nov. 4 based on the data we have today.
Put another way, the models are simply not precise enough for us to have much confidence regarding who will control the Senate on Nov. 4 based on the data we have today.
Two years back Nate Silver and I had a very constructive exchange regarding his presidential forecast model. (Interestingly, Sam Wang – whose forecast model Silver recently critiqued, also joined in on that previous exchange.) My major critique then was the lack of transparency in Silver’s model, which made it difficult for others to decipher the logic driving his predictions. For political scientists, forecasting is primarily a means to achieve a better understanding of elections more than it is an opportunity to showcase our forecasting skills, so it is imperative that we know how forecasts are constructed in order to assess their results. Since my earlier critique, however, Silver has come a long way toward showing us some of the moving parts in his models, as his post here explaining his Senate forecasts demonstrates. The ideal in this regard, however, is Wang, who generously provides the code for his forecasting model at his Princeton Election Consortium site.
So, please, take a peek at my latest post at U.S. News. And if you don’t hear from me for a while, it’s because I’m ducking the incoming twitter blast that is surely coming my way.
Addendum 8:44 p.m. Frank Lunz responds to my twitter-based defense: “Frank Luntz @FrankLuntz 5 minutes ago
@MattDickinson44 Yes, I too have had my own headache with a clickbait headline this week.” Here’s the background to his experience with what he calls clickbait.


